> ## Documentation Index
> Fetch the complete documentation index at: https://cubed3-feat-druid-driver-streaming.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Lambda pre-aggregations
> Lambda-style pre-aggregations that merge historical rollups with fresher source or streaming layers for near-real-time serving on Cube Store.
Lambda pre-aggregations follow the
[Lambda architecture](https://en.wikipedia.org/wiki/Lambda_architecture) design
to union real-time and batch data. Cube acts as a serving layer and uses
pre-aggregations as a batch layer and source data or other pre-aggregations,
usually [streaming][streaming-pre-agg], as a speed layer. Due to this design,
lambda pre-aggregations **only** work with data that is newer than the existing
batched pre-aggregations.
Lambda pre-aggregations only work with Cube Store.
## Use cases
Below we are looking at the most common examples of using lambda
pre-aggregations.
### Batch and source data
Batch data is coming from pre-aggregation and real-time data is coming from the
data source.
First, you need to create pre-aggregations that will contain your batch data. In
the following example, we call it `batch`. Please note, it must have a
`time_dimension` and `partition_granularity` specified. Cube will use these
properties to union batch data with freshly-retrieved source data.
You may also control the batch part of your data with the `build_range_start`
and `build_range_end` properties of a pre-aggregation to determine a specific
window for your batched data.
Next, you need to create a lambda pre-aggregation. To do that, create
pre-aggregation with type `rollup_lambda`, specify rollups you would like to use
with `rollups` property, and finally set `union_with_source_data: true` to use
source data as a real-time layer.
Please make sure that the lambda pre-aggregation definition comes first when
defining your pre-aggregations.
```yaml title="YAML" theme={null}
cubes:
- name: users
# ...
pre_aggregations:
- name: lambda
type: rollup_lambda
union_with_source_data: true
rollups:
- CUBE.batch
- name: batch
measures:
- users.count
dimensions:
- users.name
time_dimension: users.created_at
granularity: day
partition_granularity: day
build_range_start:
sql: SELECT '2020-01-01'
build_range_end:
sql: SELECT '2022-05-30'
```
```javascript title="JavaScript" theme={null}
cube("users", {
// ...
pre_aggregations: {
lambda: {
type: `rollup_lambda`,
union_with_source_data: true,
rollups: [CUBE.batch]
},
batch: {
measures: [users.count],
dimensions: [users.name],
time_dimension: users.created_at,
granularity: `day`,
partition_granularity: `day`,
build_range_start: {
sql: `SELECT '2020-01-01'`
},
build_range_end: {
sql: `SELECT '2022-05-30'`
}
}
}
})
```
### Batch and streaming data
In this scenario, batch data is comes from one pre-aggregation and real-time
data comes from a [streaming pre-aggregation][streaming-pre-agg].
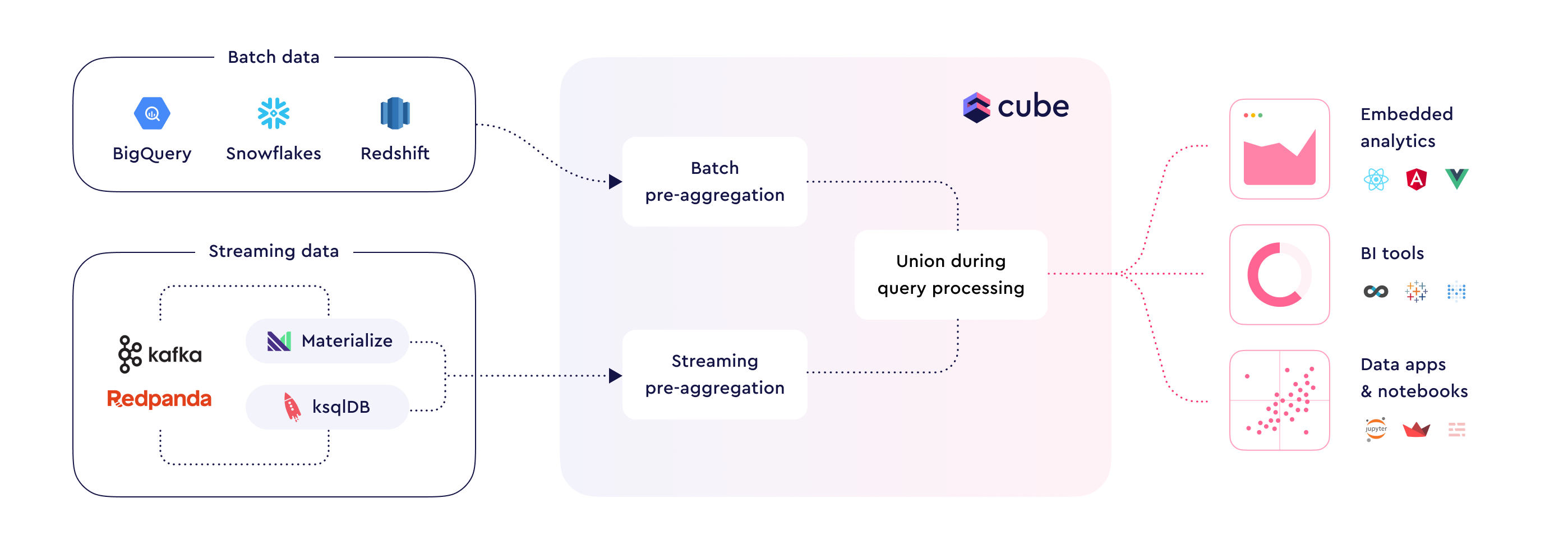
You can use lambda pre-aggregations to combine data from multiple
pre-aggregations, where one pre-aggregation can have batch data and another
streaming.
Please note that build ranges of all rollups referenced by lambda rollup should have enough intersection between each other that anticipates partition build times for those rollups.
Cube will maximize the coverage of the requested date range by partitions from different rollups.
The first rollup in a list of referenced rollups that has a fully built partition for a particular date range will be used to serve this date range.
The last rollup in a list will be used to cover the remaining uncovered part of a date range.
Partitions of the last rollup will be used even if not completely built.
```yaml title="YAML" theme={null}
cubes:
- name: streaming_users
# This cube uses a streaming SQL data source such as ksqlDB
# ...
pre_aggregations:
- name: streaming
type: rollup
measures:
- CUBE.count
dimensions:
- CUBE.name
time_dimension: CUBE.created_at
granularity: day,
partition_granularity: day
- name: users
# This cube uses a data source such as ClickHouse or BigQuery
# ...
pre_aggregations:
- name: batch_streaming_lambda
type: rollup_lambda
rollups:
- users.batch
- streaming_users.streaming
- name: batch
type: rollup
measures:
- users.count
dimensions:
- users.name
time_dimension: users.created_at
granularity: day
partition_granularity: day
build_range_start:
sql: SELECT '2020-01-01'
build_range_end:
sql: SELECT '2022-05-30'
```
```javascript title="JavaScript" theme={null}
// This cube uses a streaming SQL data source such as ksqlDB
cube("streaming_users", {
// ...
pre_aggregations: {
streaming: {
type: `rollup`,
measures: [CUBE.count],
dimensions: [CUBE.name],
time_dimension: CUBE.created_at,
granularity: `day`,
partition_granularity: `day`
}
}
})
// This cube uses a data source such as ClickHouse or BigQuery
cube("users", {
// ...
pre_aggregations: {
batch_streaming_lambda: {
type: `rollup_lambda`,
rollups: [users.batch, streaming_users.streaming]
},
batch: {
type: `rollup`,
measures: [users.count],
dimensions: [users.name],
time_dimension: users.created_at,
granularity: `day`,
partition_granularity: `day`,
build_range_start: {
sql: `SELECT '2020-01-01'`
},
build_range_end: {
sql: `SELECT '2022-05-30'`
}
}
}
})
```
[streaming-pre-agg]: /docs/pre-aggregations/using-pre-aggregations#streaming-pre-aggregations