> ## Documentation Index
> Fetch the complete documentation index at: https://cubed3-feat-druid-driver-streaming.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Orchestration API
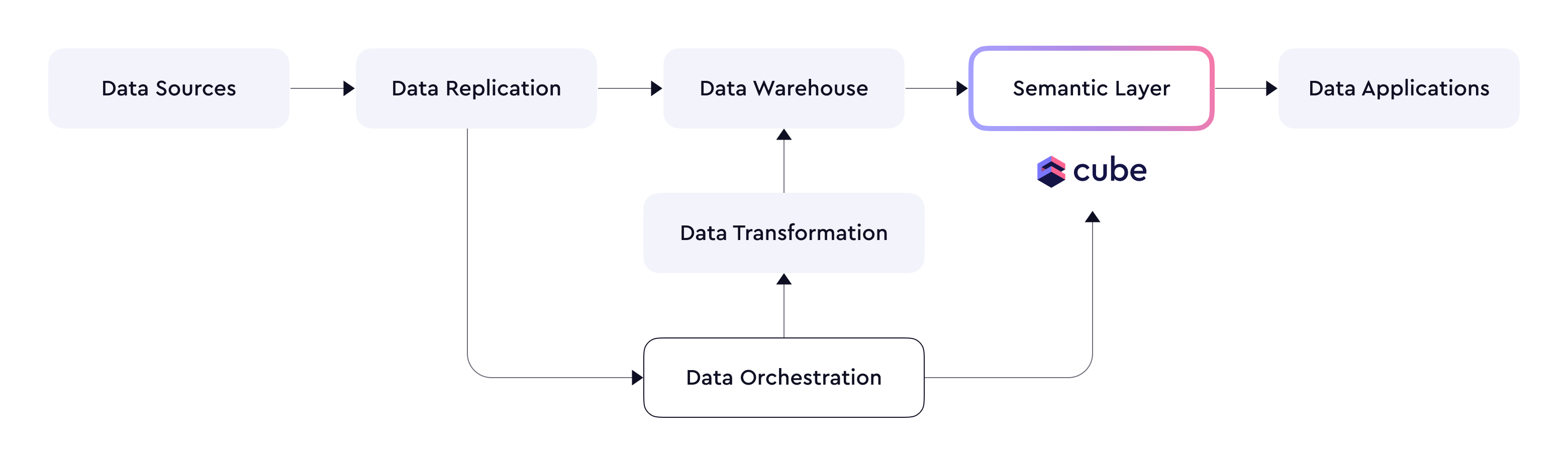
> Trigger pre-aggregation refreshes from Airflow, Dagster, or Prefect instead of relying on Cube's scheduled refresh.
Orchestration API enables Cube to work with data orchestration tools and let
them *push* changes from upstream data sources to Cube, as opposed to letting
Cube *pull* changes from upstream data sources via the
[`scheduledRefresh`][ref-scheduled-refresh] configration option of
pre-aggregations.
 Orchestration API can be used to implement both [embedded analytics][cube-ea]
and internal or self-serve [business intelligence][cube-issbi] use cases. When
implementing [real-time analytics][cube-rta], consider pulling data from
upstream data sources with [lambda pre-aggregations][ref-lambda-pre-aggs].
Under the hood, the Orchestration API is exposed via the
[`/v1/pre-aggregations/jobs`][ref-ref-jobs-endpoint] endpoint of the
[REST (JSON) API][ref-rest-api].
## Supported tools
Orchestration API has integration packages to work with popular data
orchestration tools. Check the following guides to get tool-specific
instructions:
Trigger pre-aggregation builds from Apache Airflow DAGs.
Trigger pre-aggregation builds from Dagster assets and jobs.
Trigger pre-aggregation builds from Prefect flows.
## Configuration
Orchestration API is enabled by default but inaccessible due to the default [API
scopes][ref-api-scopes] configuration. To allow access to the Orchestration API,
enable the `jobs` scope, e.g., by setting the [`CUBEJS_DEFAULT_API_SCOPES`](/reference/configuration/environment-variables#cubejs_default_api_scopes)
environment variable to `meta,data,graphql,jobs`.
## Building pre-aggregations
Orchestration API allows to trigger pre-aggregation builds programmatically. It
can be useful for data orchestration tools to push changes from upstream data
sources to Cube or for any third parties to invalidate and rebuild
pre-aggregations on demand.
You can trigger pre-aggregation builds and check build statuses using the
[`/v1/pre-aggregations/jobs`][ref-ref-jobs-endpoint] endpoint. It is possible to
rebuild all pre-aggregations or specify the ones to be rebuilt:
* Particular pre-aggregations.
* Pre-aggregations that reference particular cubes.
* Pre-aggregations that reference cubes from particular data sources.
* For [partitioned pre-aggregations][ref-pre-agg-partitions], only partitions that contain
data from a particular date range.
[ref-scheduled-refresh]: /reference/data-modeling/pre-aggregations#scheduled_refresh
[cube-ea]: https://cube.dev/use-cases/embedded-analytics
[cube-issbi]: https://cube.dev/use-cases/semantic-layer
[cube-rta]: https://cube.dev/use-cases/real-time-analytics
[ref-lambda-pre-aggs]: /docs/pre-aggregations/lambda-pre-aggregations
[ref-rest-api]: /reference/core-data-apis/rest-api
[ref-api-scopes]: /reference/core-data-apis/rest-api#configuration-api-scopes
[ref-ref-jobs-endpoint]: /reference/core-data-apis/rest-api/reference#base_path/v1/pre-aggregations/jobs
[ref-pre-agg-partitions]: /docs/pre-aggregations/using-pre-aggregations#partitioning
Orchestration API can be used to implement both [embedded analytics][cube-ea]
and internal or self-serve [business intelligence][cube-issbi] use cases. When
implementing [real-time analytics][cube-rta], consider pulling data from
upstream data sources with [lambda pre-aggregations][ref-lambda-pre-aggs].
Under the hood, the Orchestration API is exposed via the
[`/v1/pre-aggregations/jobs`][ref-ref-jobs-endpoint] endpoint of the
[REST (JSON) API][ref-rest-api].
## Supported tools
Orchestration API has integration packages to work with popular data
orchestration tools. Check the following guides to get tool-specific
instructions:
Trigger pre-aggregation builds from Apache Airflow DAGs.
Trigger pre-aggregation builds from Dagster assets and jobs.
Trigger pre-aggregation builds from Prefect flows.
## Configuration
Orchestration API is enabled by default but inaccessible due to the default [API
scopes][ref-api-scopes] configuration. To allow access to the Orchestration API,
enable the `jobs` scope, e.g., by setting the [`CUBEJS_DEFAULT_API_SCOPES`](/reference/configuration/environment-variables#cubejs_default_api_scopes)
environment variable to `meta,data,graphql,jobs`.
## Building pre-aggregations
Orchestration API allows to trigger pre-aggregation builds programmatically. It
can be useful for data orchestration tools to push changes from upstream data
sources to Cube or for any third parties to invalidate and rebuild
pre-aggregations on demand.
You can trigger pre-aggregation builds and check build statuses using the
[`/v1/pre-aggregations/jobs`][ref-ref-jobs-endpoint] endpoint. It is possible to
rebuild all pre-aggregations or specify the ones to be rebuilt:
* Particular pre-aggregations.
* Pre-aggregations that reference particular cubes.
* Pre-aggregations that reference cubes from particular data sources.
* For [partitioned pre-aggregations][ref-pre-agg-partitions], only partitions that contain
data from a particular date range.
[ref-scheduled-refresh]: /reference/data-modeling/pre-aggregations#scheduled_refresh
[cube-ea]: https://cube.dev/use-cases/embedded-analytics
[cube-issbi]: https://cube.dev/use-cases/semantic-layer
[cube-rta]: https://cube.dev/use-cases/real-time-analytics
[ref-lambda-pre-aggs]: /docs/pre-aggregations/lambda-pre-aggregations
[ref-rest-api]: /reference/core-data-apis/rest-api
[ref-api-scopes]: /reference/core-data-apis/rest-api#configuration-api-scopes
[ref-ref-jobs-endpoint]: /reference/core-data-apis/rest-api/reference#base_path/v1/pre-aggregations/jobs
[ref-pre-agg-partitions]: /docs/pre-aggregations/using-pre-aggregations#partitioning